mirror of
https://github.com/HIllya51/LunaTranslator.git
synced 2025-11-28 09:00:23 +08:00
47 lines
No EOL
3.5 KiB
Markdown
47 lines
No EOL
3.5 KiB
Markdown
# さまざまな翻訳最適化の役割
|
|
|
|
1. ## 固有名詞翻訳 {#anchor-noundict}
|
|
|
|
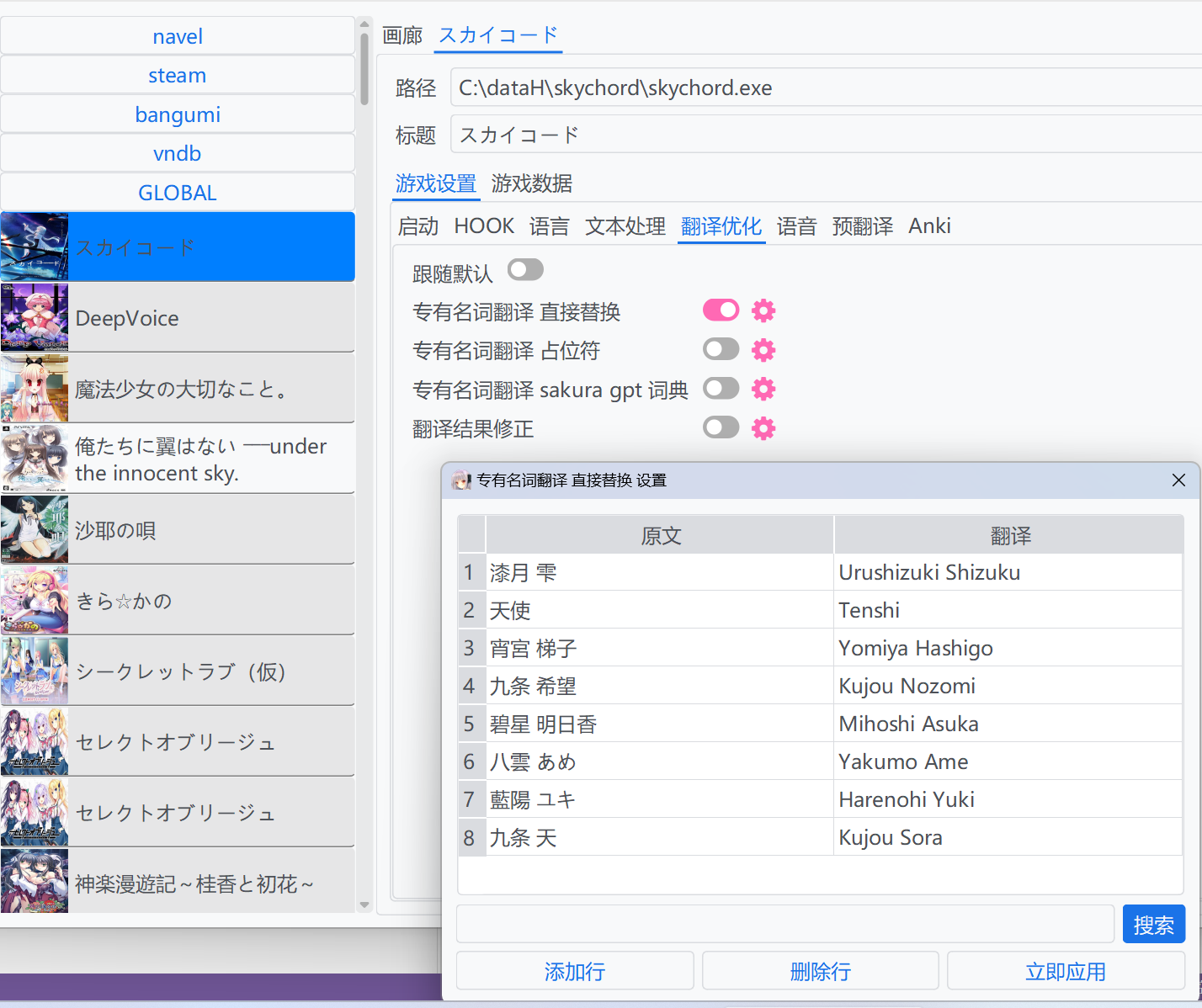
この方法は、翻訳前に元のテキストを翻訳されたテキストに直接置き換えます。より複雑な置換には `Regex` や `Escape` を使用することができます。
|
|
|
|
ゲームがVNDBからメタデータを読み込む際、ゲーム内の人名情報をクエリしてプリセット辞書として設定します。英語ユーザーの場合、抽出された英語名を原文に対応する翻訳として入力します。それ以外の場合、ユーザーが変更を加えない場合に翻訳に影響を与えないように、翻訳を原文と同じ内容で入力します。
|
|
|
|
::: details 例
|
|
|
|
:::
|
|
|
|
1. ## 固有名詞翻訳 {#anchor-noundict}
|
|
|
|
`sakura large model` を使用し、プロンプト形式をgpt辞書プロンプトをサポートするように設定すると、gpt辞書形式に変換されます。それ以外の場合は、VNRアプローチを参照し、元のテキストをプレースホルダー `ZX?Z` に置き換えます(注:これが何を意味するのかはわかりません)。ソース翻訳後、プレースホルダーは通常破壊されません。その後、翻訳後にプレースホルダーが翻訳に置き換えられます。
|
|
|
|
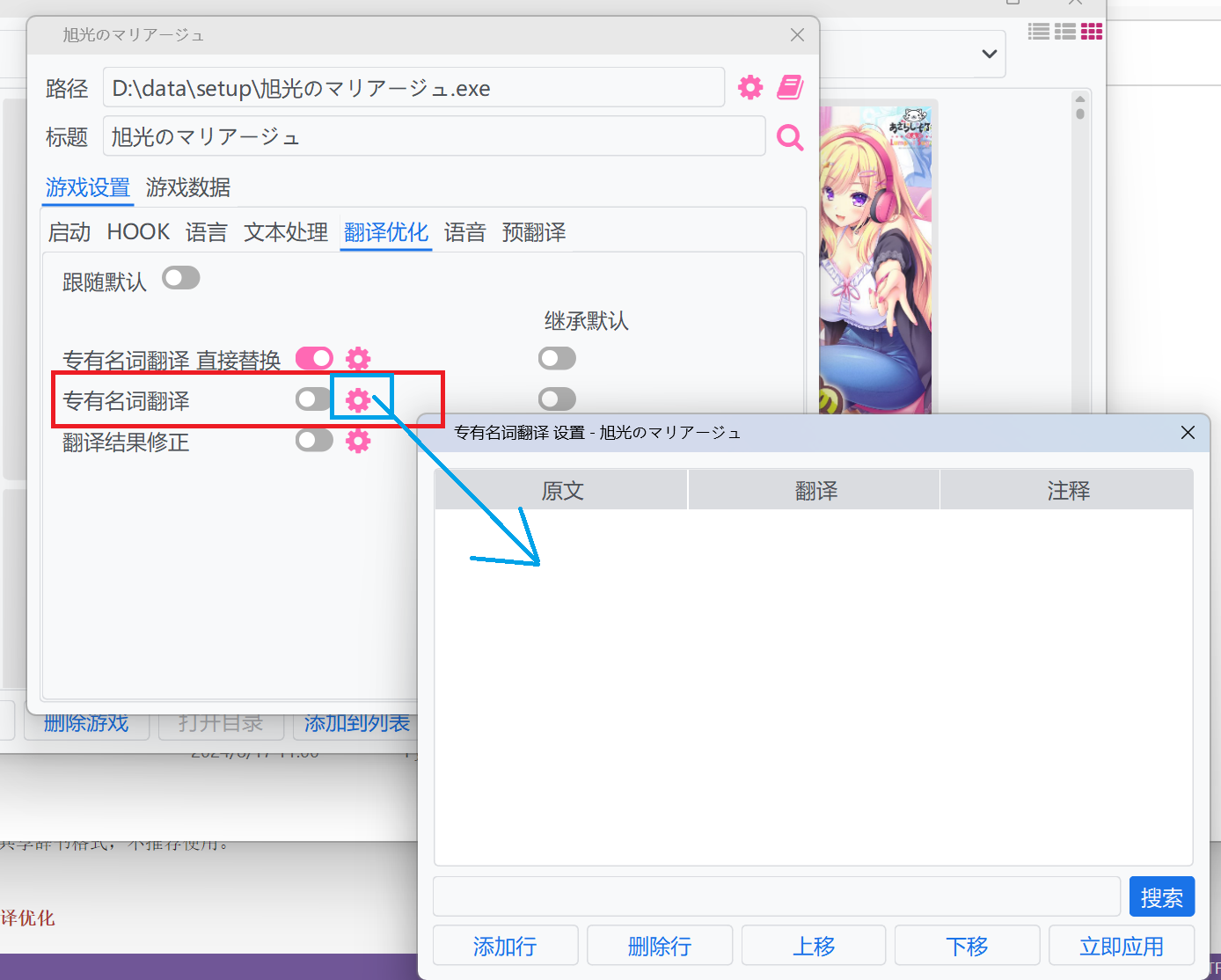
ゲーム固有のエントリについては、 `テキスト処理` -> `翻訳最適化` に追加しないことをお勧めします。過去には、ゲームのmd5値を使用して複数のゲームのエントリを区別していましたが、この実装はあまり良くなく、廃止されました。現在、この方法の設定で `ゲーム設定` -> `翻訳最適化` にゲーム固有のエントリを追加することをお勧めします。
|
|
|
|
最後の列 `コメント` は `Sakura Large Model` のみで使用され、他の翻訳ではこの列は無視されます。
|
|
|
|
ゲームがVNDBからメタデータを読み込む際、ゲーム内の人名情報をクエリしてプリセット辞書として設定します。英語ユーザーの場合、抽出された英語を原文に対応する翻訳として入力します。それ以外の場合は、ユーザーが変更を加えない場合に翻訳に影響を与えないように、翻訳を空のままにします。
|
|
|
|
::: details ゲーム固有のエントリの設定
|
|
次のように設定することをお勧めします:
|
|
|
|
次のように設定しないでください:
|
|
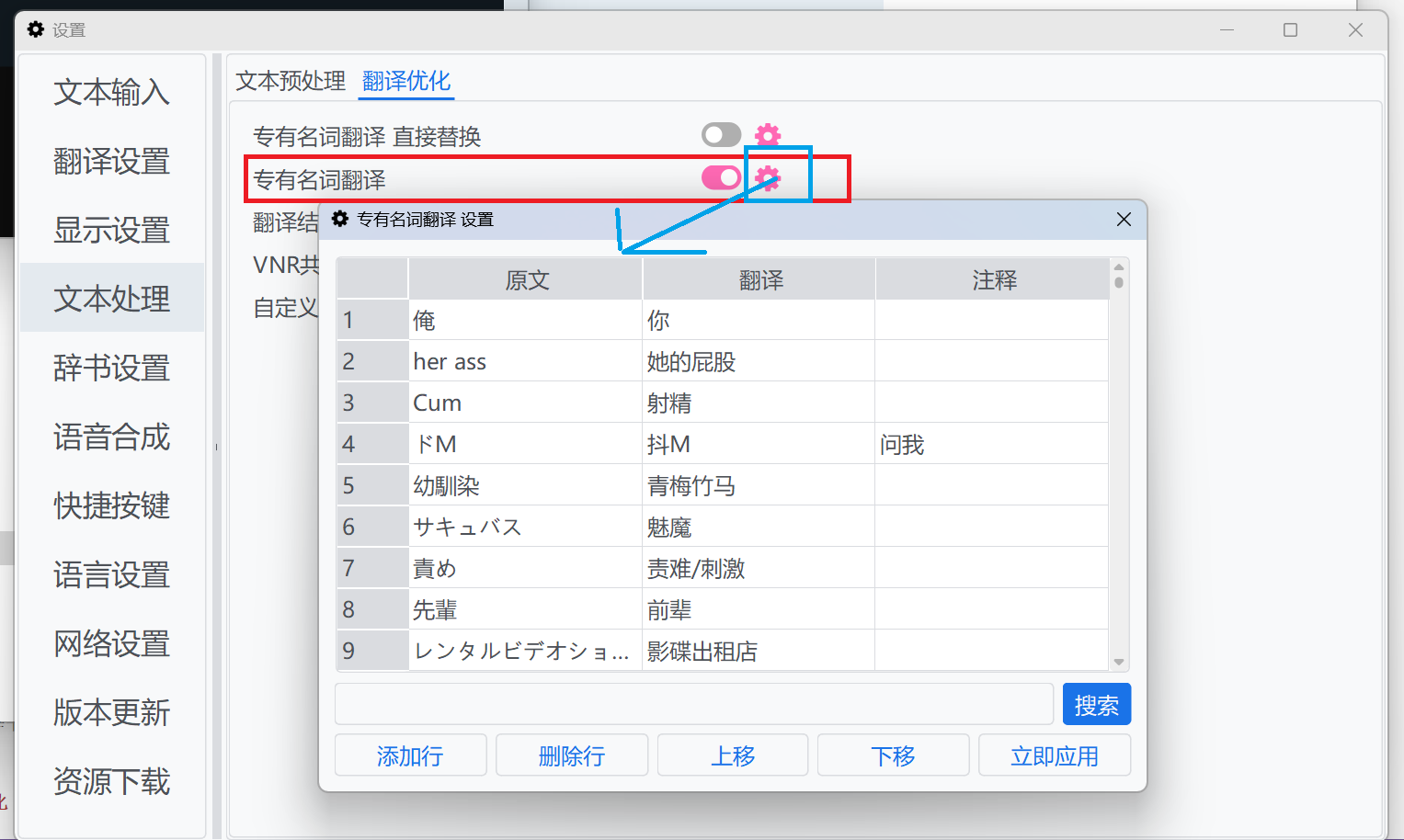
|
|
:::
|
|
|
|
|
|
1. ## 翻訳結果の修正 {#anchor-transerrorfix}
|
|
|
|
この方法は、翻訳後に翻訳結果に対して特定の修正を行うことができ、複雑な修正には全体の表現を使用することができます。
|
|
|
|
1. ## カスタム最適化 {#anchor-myprocess}
|
|
|
|
Pythonスクリプトを作成して、より複雑な処理を実行する
|
|
|
|
1. ## 句読点のみを含む文をスキップする {#anchor-skiponlypunctuations}
|
|
|
|
該当なし
|
|
|
|
## ゲーム固有の翻訳最適化
|
|
|
|
`ゲーム設定` -> `翻訳最適化` で `デフォルトに従う` を無効にすると、ゲーム固有の翻訳最適化設定が使用されます。
|
|
|
|
`デフォルトを継承` を有効にすると、ゲーム固有の翻訳最適化辞書もデフォルトのグローバル辞書を使用します。 |