mirror of
https://github.com/HIllya51/LunaTranslator.git
synced 2025-11-28 09:00:23 +08:00
50 lines
No EOL
2.6 KiB
Markdown
50 lines
No EOL
2.6 KiB
Markdown
# 各种翻译优化的作用
|
||
|
||
1. ## 专有名词翻译 {#anchor-noundict}
|
||
|
||
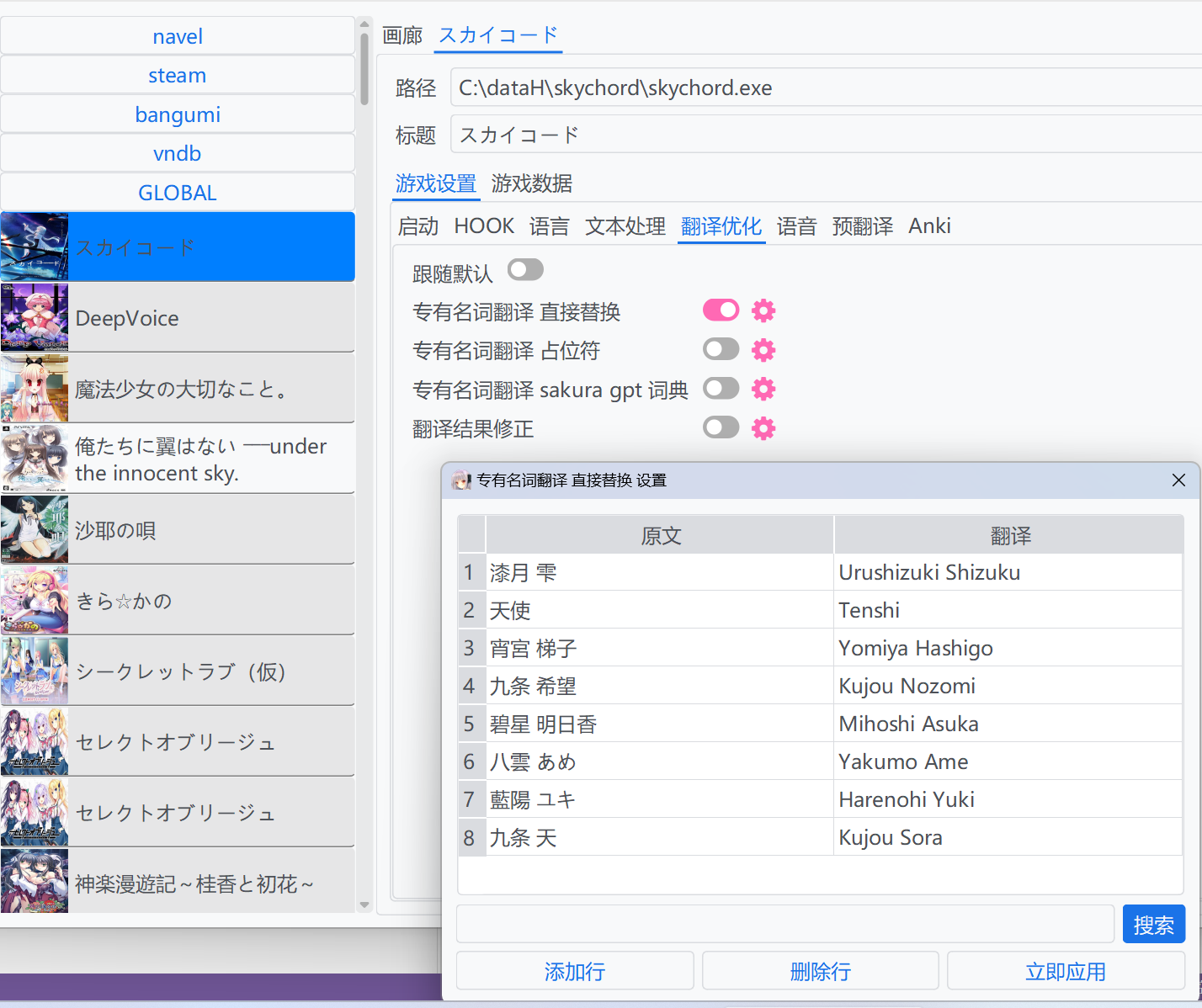
这种方法会在翻译之前,直接用译文将原文进行替换。支持使用`正则` `转义`进行更复杂的替换。
|
||
|
||
当游戏从VNDB加载元数据时,会查询游戏中的人名信息作为预设的词典。对于英文用户,会填充提取到的英文作为原文对应的翻译,否则会填充翻译为和原文相同的内容以避免在用户不进行修改时影响翻译。
|
||
|
||
::: details 示例
|
||
|
||
:::
|
||
|
||
|
||
1. ## 专有名词翻译 {#anchor-noundict}
|
||
|
||
如果使用`sakura大模型`并设置prompt格式为支持gpt词典的prompt,则会转换成gpt词典格式,否则会参考的VNR的做法,将原文替换为占位符`ZX?Z` (ps:我也不知道这是什么意思),翻译源翻译后一般不会将占位符破坏,然后在翻译后将占位符替换成翻译。
|
||
|
||
对于游戏的专用词条,建议不要在文本处理->翻译优化中添加。过去使用游戏的md5值来区分多个游戏的词条,但这样的实现其实不是很好,已经废弃这样的实现。现在建议在`游戏设置`中的`翻译优化`中的该方法的设置中,添加游戏专用的词条。
|
||
|
||
最后一列`注释`仅用于给`sakura大模型`使用,其他翻译会无视这一列。
|
||
|
||
当游戏从VNDB加载元数据时,会查询游戏中的人名信息作为预设的词典。对于英文用户,会填充提取到的英文作为原文对应的翻译,否则会填充翻译为空以避免在用户不进行修改时影响翻译。
|
||
|
||
::: details 设置游戏的专用词条
|
||
建议使用:
|
||
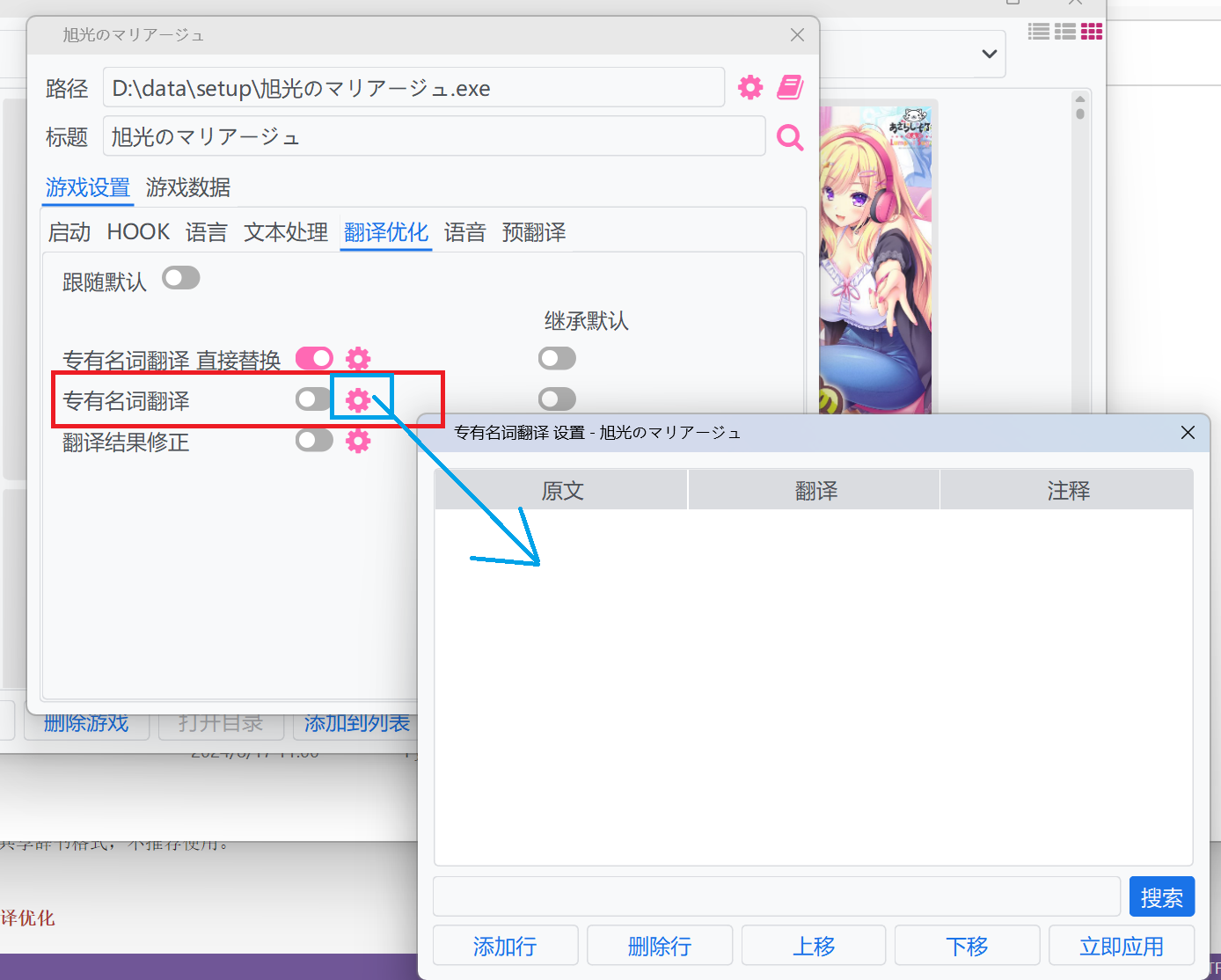
|
||
而不是:
|
||
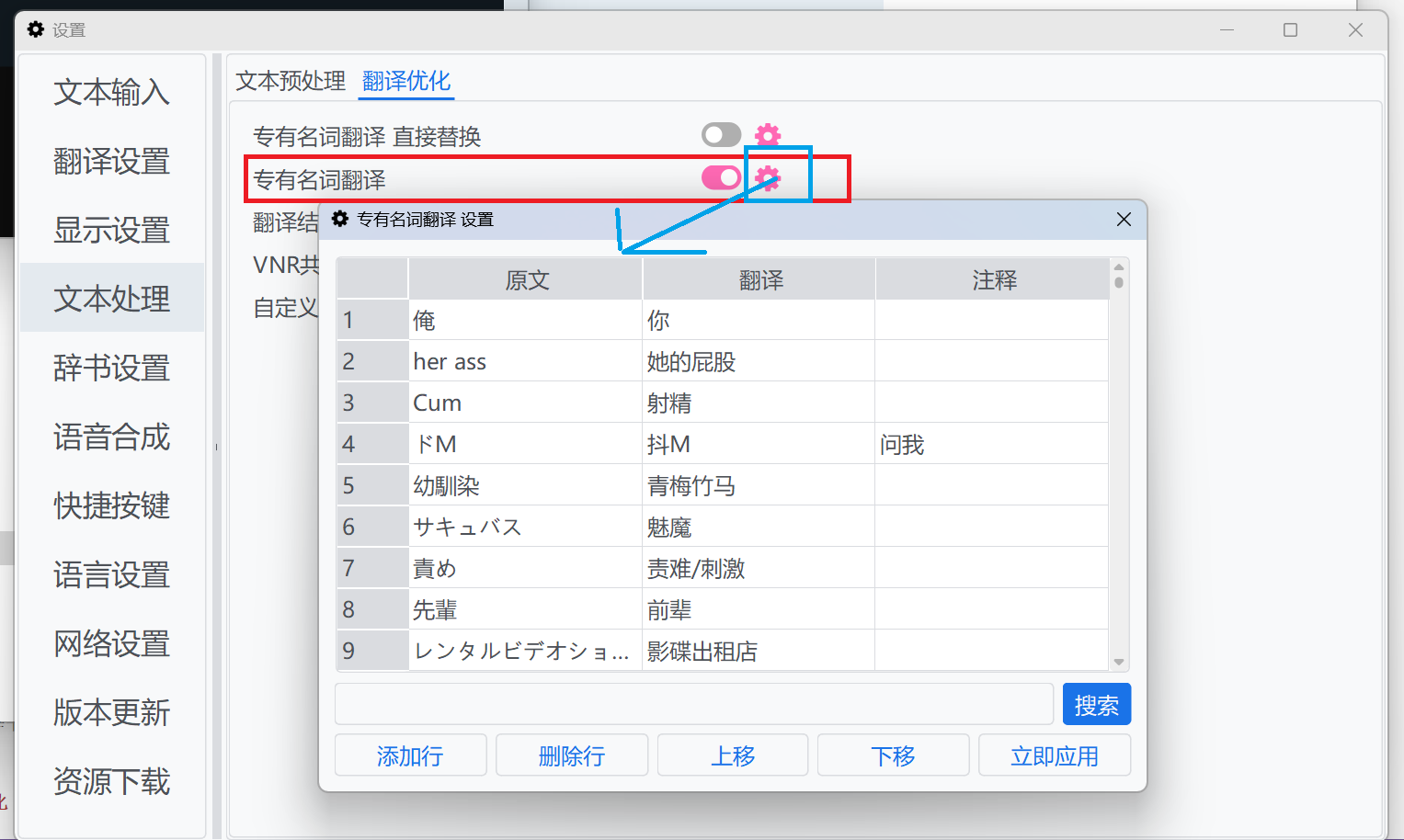
|
||
:::
|
||
::: details sakura大模型设置prompt格式为v0.10pre1(支持gpt词典)
|
||
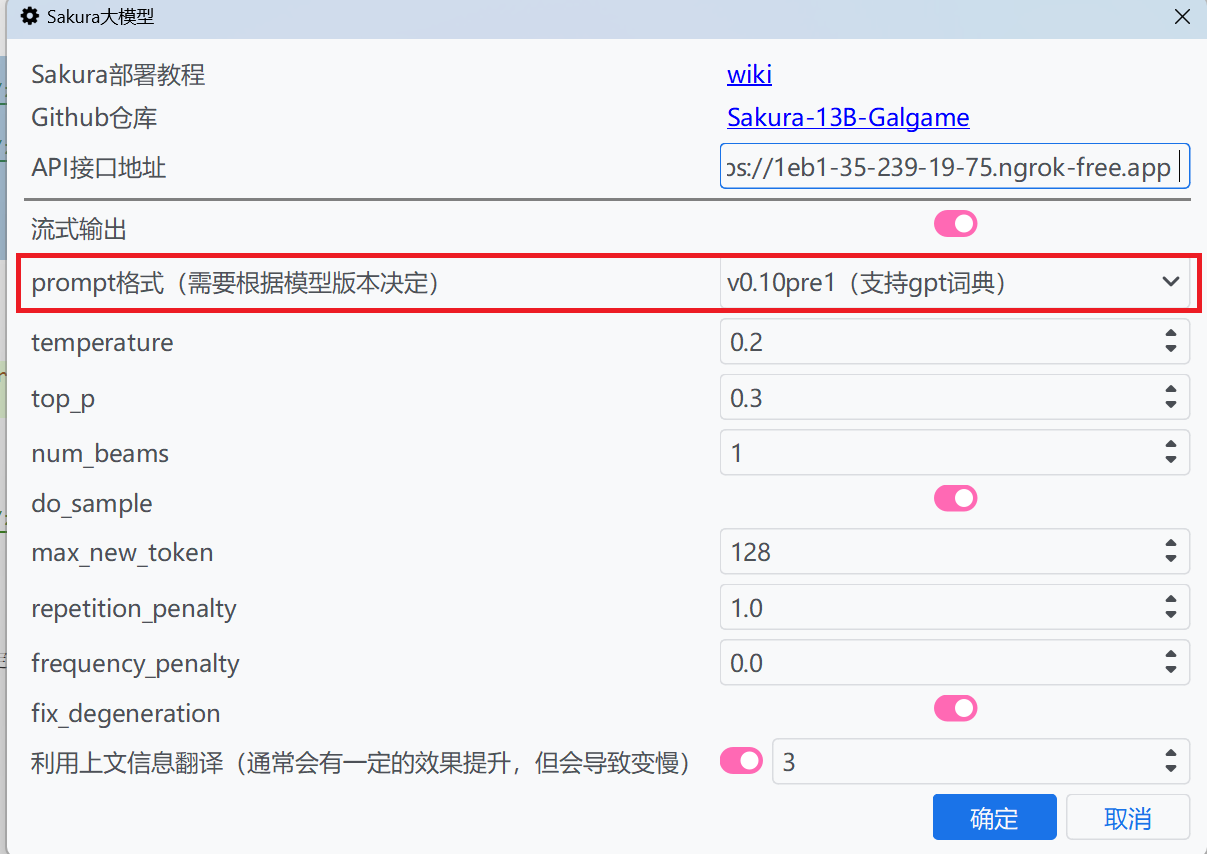
|
||
:::
|
||
|
||
1. ## 翻译结果修正 {#anchor-transerrorfix}
|
||
|
||
这个方法是,在翻译完毕后,可以对翻译的结果进行一定的修正,并可以使用整个表达式进行复杂的修正。
|
||
|
||
1. ## 自定义优化 {#anchor-myprocess}
|
||
|
||
撰写一个python脚本来进行更加复杂的处理
|
||
|
||
1. ## 跳过仅包含标点的句子 {#anchor-skiponlypunctuations}
|
||
|
||
略
|
||
|
||
## 游戏专用翻译优化
|
||
|
||
在`游戏设置`->`翻译优化`中,若取消激活跟随默认,则会使用游戏专用的翻译优化设置。
|
||
|
||
若激活`继承默认`,则在游戏专用翻译优化的词典之外,也会同时使用默认的全局词典。 |