mirror of
https://github.com/HIllya51/LunaTranslator.git
synced 2025-11-28 09:00:23 +08:00
50 lines
No EOL
2.7 KiB
Markdown
50 lines
No EOL
2.7 KiB
Markdown
# 各種翻譯優化的作用
|
||
|
||
1. ## 專有名詞翻譯 {#anchor-noundict}
|
||
|
||
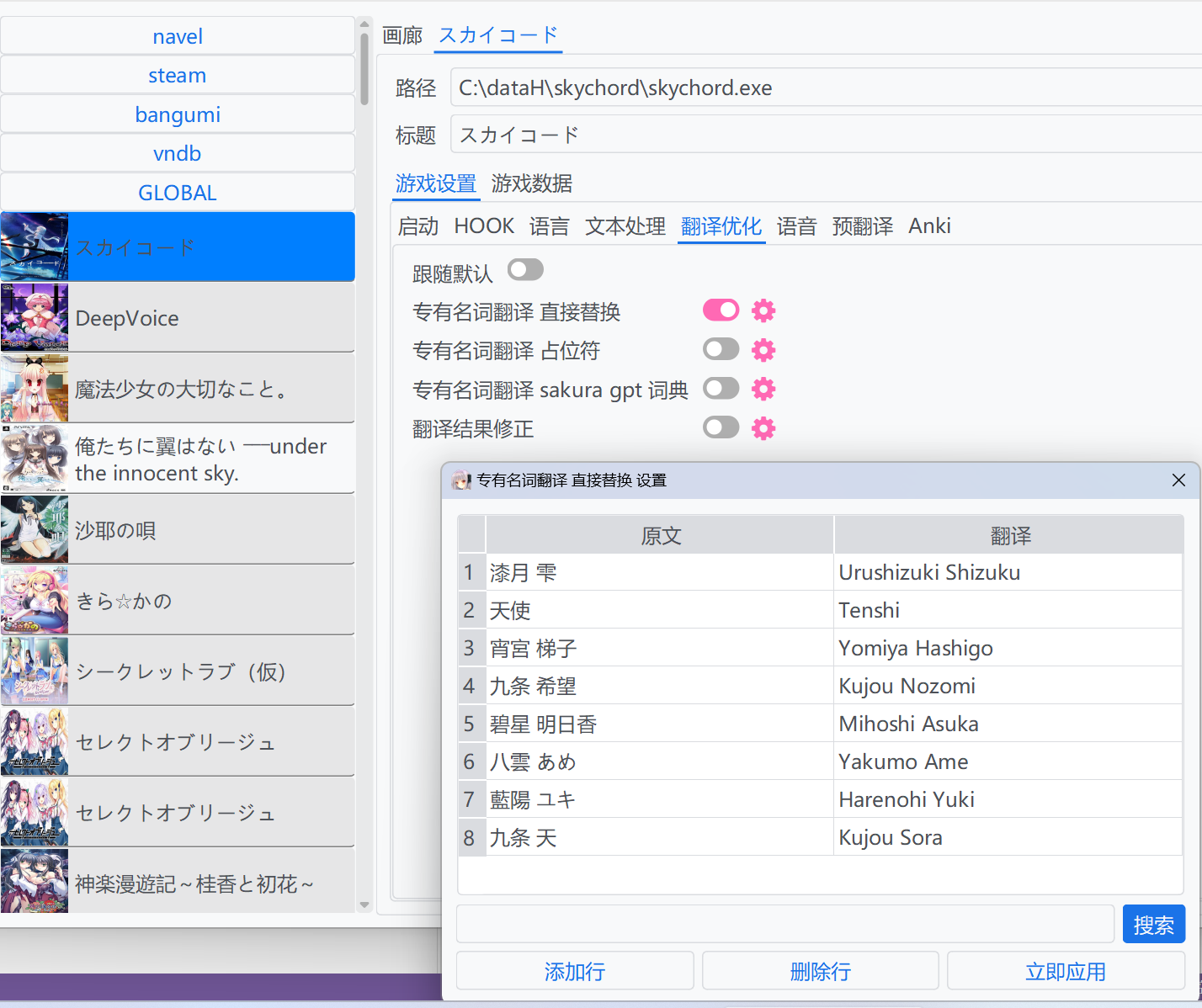
這種方法會在翻譯之前,直接用譯文將原文進行取代。支援使用`正則` `跳脫`進行更複雜的取代。
|
||
|
||
當從 VNDB 載入中繼資料時,遊戲會查詢角色名稱資訊並設定為預設詞典。對於英文使用者,提取的英文名稱會被填入作為原文對應的翻譯。否則,為了在使用者未進行修改時不影響翻譯,翻譯內容將填入與原文相同的內容。
|
||
|
||
::: details 範例
|
||
|
||
:::
|
||
|
||
|
||
1. ## 專有名詞翻譯 {#anchor-noundict}
|
||
|
||
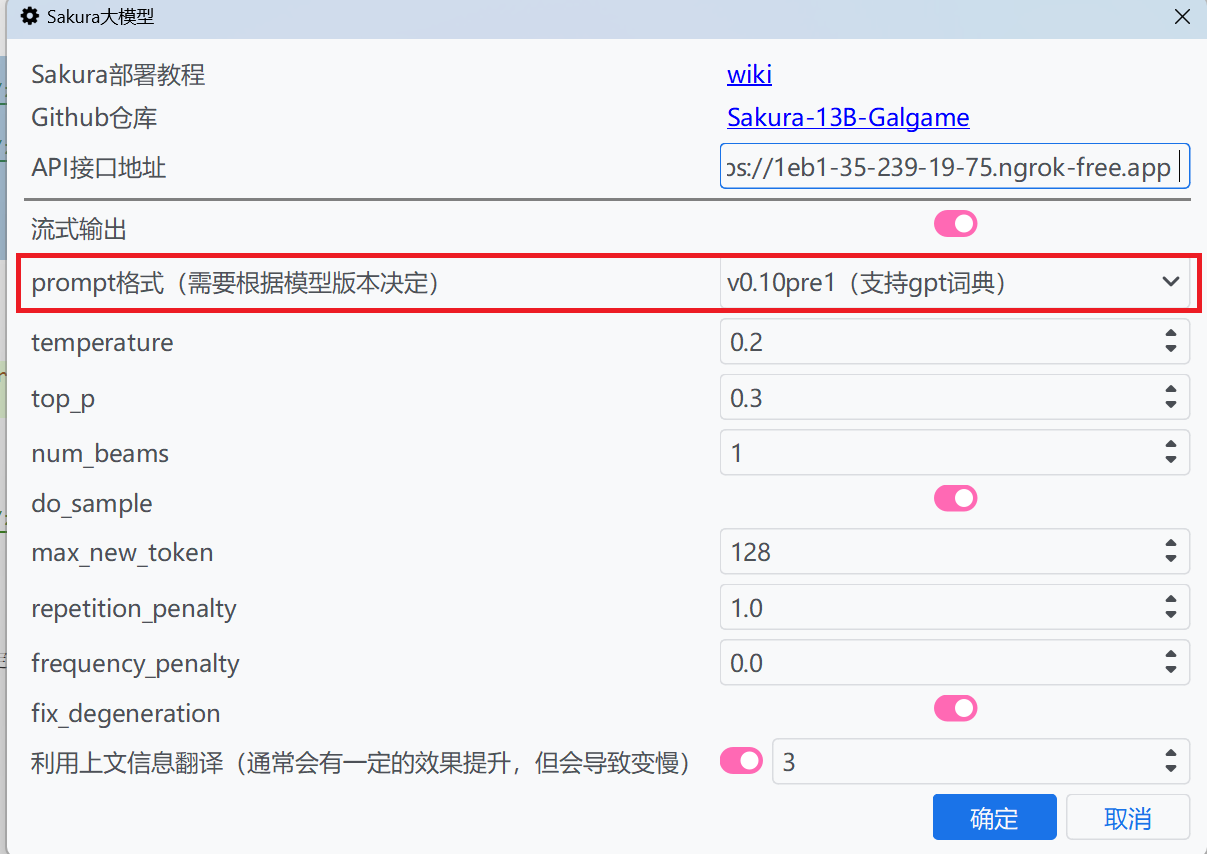
如果使用`Sakura 大模型`並設定 Prompt 格式為支援 GPT 詞典的 Prompt,則會轉換成 GPT 詞典格式,否則會參考的 VNR 的做法,將原文取代為佔位符號`ZX?Z`(PS:我也不知道這是什麼意思),翻譯來源翻譯後一般不會將佔位符號破壞,然後在翻譯後將佔位符號取代成翻譯。
|
||
|
||
對於遊戲的專用詞條,建議不要在文字處理->翻譯優化中新增。過去使用遊戲的 MD5 值來區分多個遊戲的詞條,但這樣的實現其實不是很好,因此已經廢棄這樣的實現。現在建議在`遊戲設定`中的`翻譯優化`中的該方法的設定中,新增遊戲專用的詞條。
|
||
|
||
最後一列`註釋`僅用於給`Sakura 大模型`使用,其他翻譯會無視這一欄。
|
||
|
||
遊戲從 VNDB 載入中繼資料時,會查詢遊戲中的人物名稱資訊作為預設詞典。對於英文使用者,會將提取到的英文填入作為原文對應的翻譯,否則會將翻譯留空,以避免在使用者未進行修改時影響翻譯。
|
||
|
||
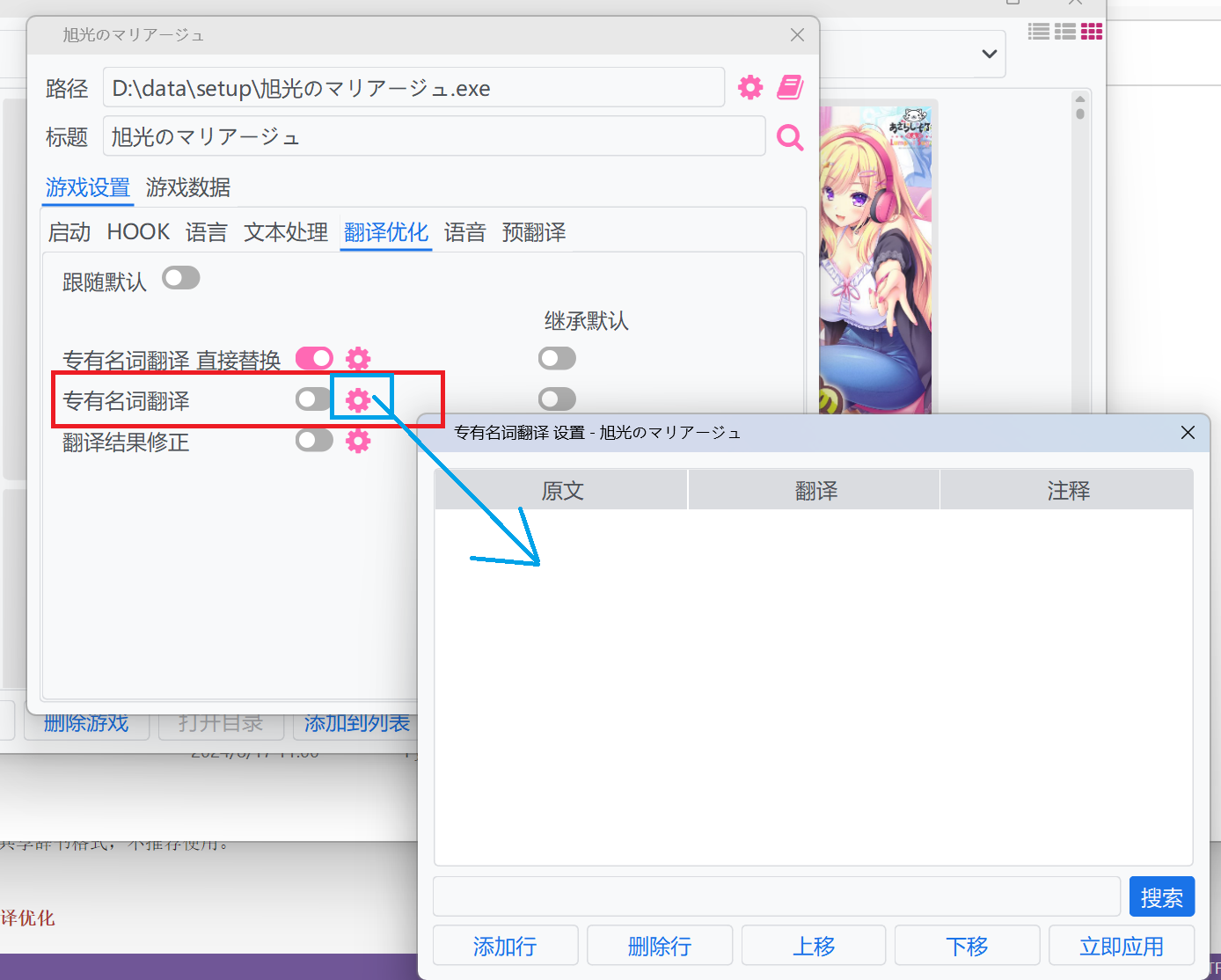
::: details 設定遊戲的專用詞條
|
||
建議使用:
|
||
|
||
而不是:
|
||
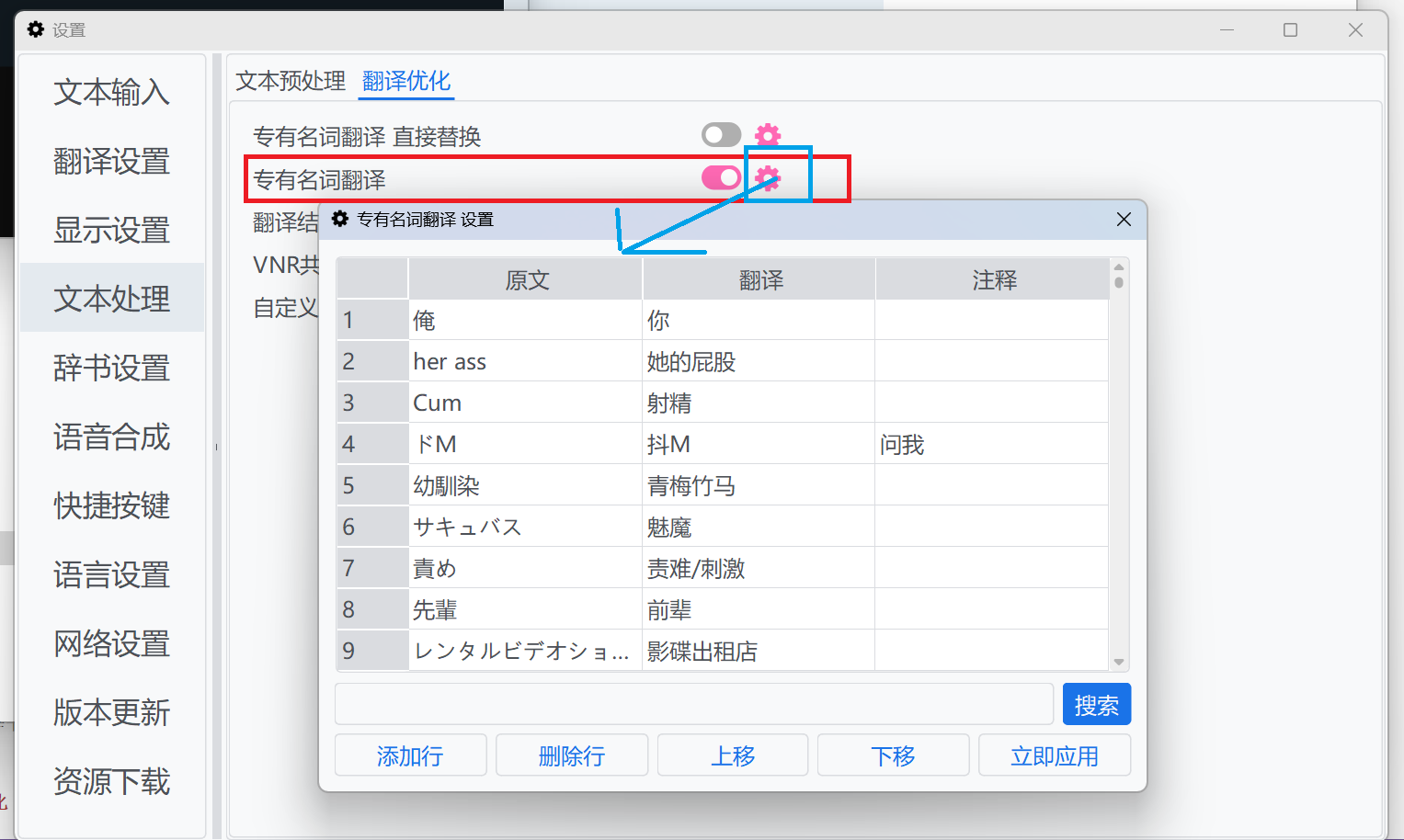
|
||
:::
|
||
::: details Sakura 大模型設定 Prompt 格式為非 v0.9 以外的版本,以支援 GPT 詞典
|
||
|
||
:::
|
||
|
||
1. ## 翻譯結果修正 {#anchor-transerrorfix}
|
||
|
||
這個方法是,在翻譯完畢後,可以對翻譯的結果進行一定的修正,並可以使用整個表達式進行複雜的修正。
|
||
|
||
1. ## 自訂優化 {#anchor-myprocess}
|
||
|
||
撰寫一個 Python 腳本來進行更複雜的處理。
|
||
|
||
1. ## 跳過僅包含標點符號的句子 {#anchor-skiponlypunctuations}
|
||
|
||
略
|
||
|
||
## 遊戲專用翻譯優化
|
||
|
||
在`遊戲設定`->`翻譯優化`中,若取消啟用`跟隨預設`,則會使用遊戲專用的翻譯優化設定。
|
||
|
||
若啟用`繼承預設`,則在遊戲專用翻譯優化的詞典之外,也會同時使用預設的全域詞典。 |